GA4 流量涨了 30%,我兴奋了十秒钟——拆开一看全是新加坡机器人
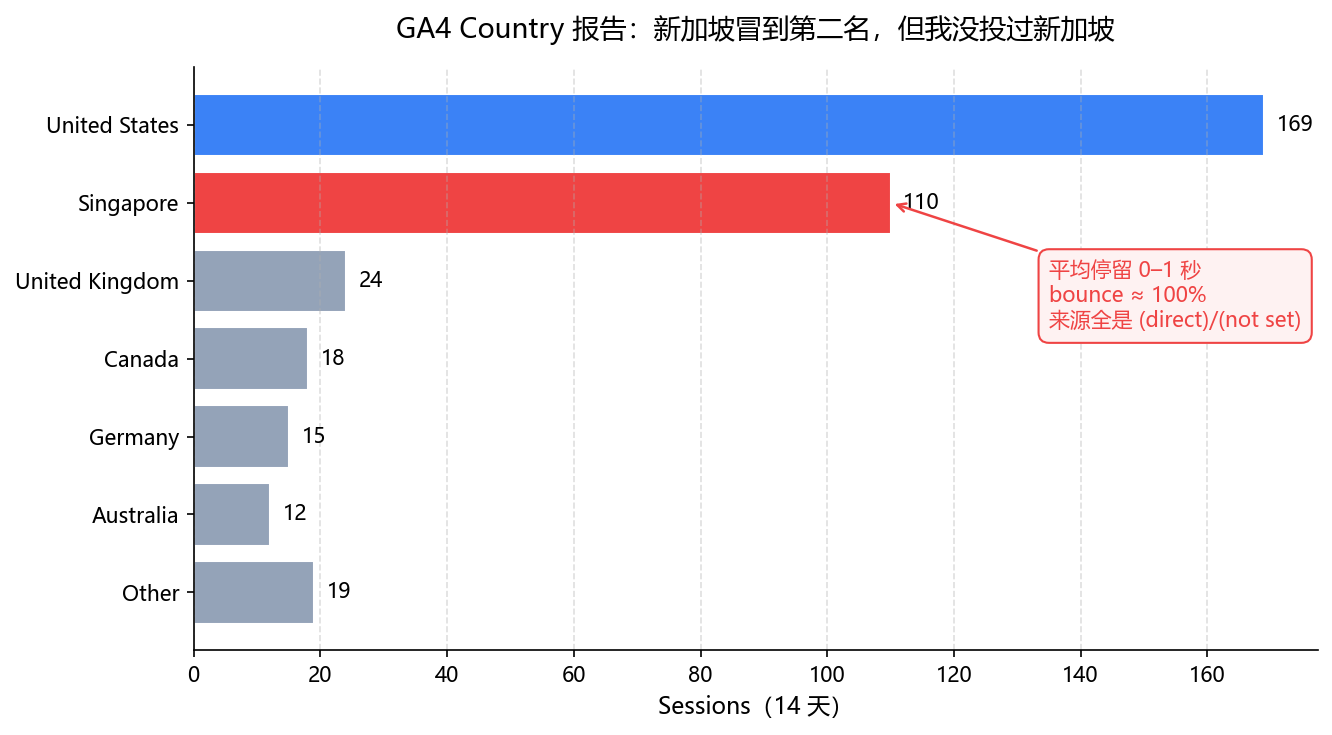
那天早上我打开 GA4,sessions 比上个月涨了快三成。
我兴奋了大概十秒钟,开始想是不是哪篇博客被搜索引擎推上去了,要不要赶紧再补一篇接住这波流量。
然后我点进 Country 报告,当场懵逼。
涨上来的那批流量,90% 来自新加坡,平均停留 0 到 1 秒,bounce 接近 100%。我没投过新加坡,没在新加坡做过任何分发,连一个新加坡客户都没有。
切到 Clarity(微软出的免费工具,会录用户 session 视频,零配置接到独立站上)想看看这些”用户”在站里干嘛——一个 session 录像都没有。
GA 看得到,Clarity 看不到。这只能说明一件事。
这篇花你 8 分钟,读完能搞清楚:怎么识别 bot 流量、为什么 GA4 自带过滤救不了你、扣掉之后真实数据长什么样、每月怎么花十分钟做这个体检。
差点踩进去的两个坑
意识到这件事之前,我已经在两个错误结论的路上各走了半天。
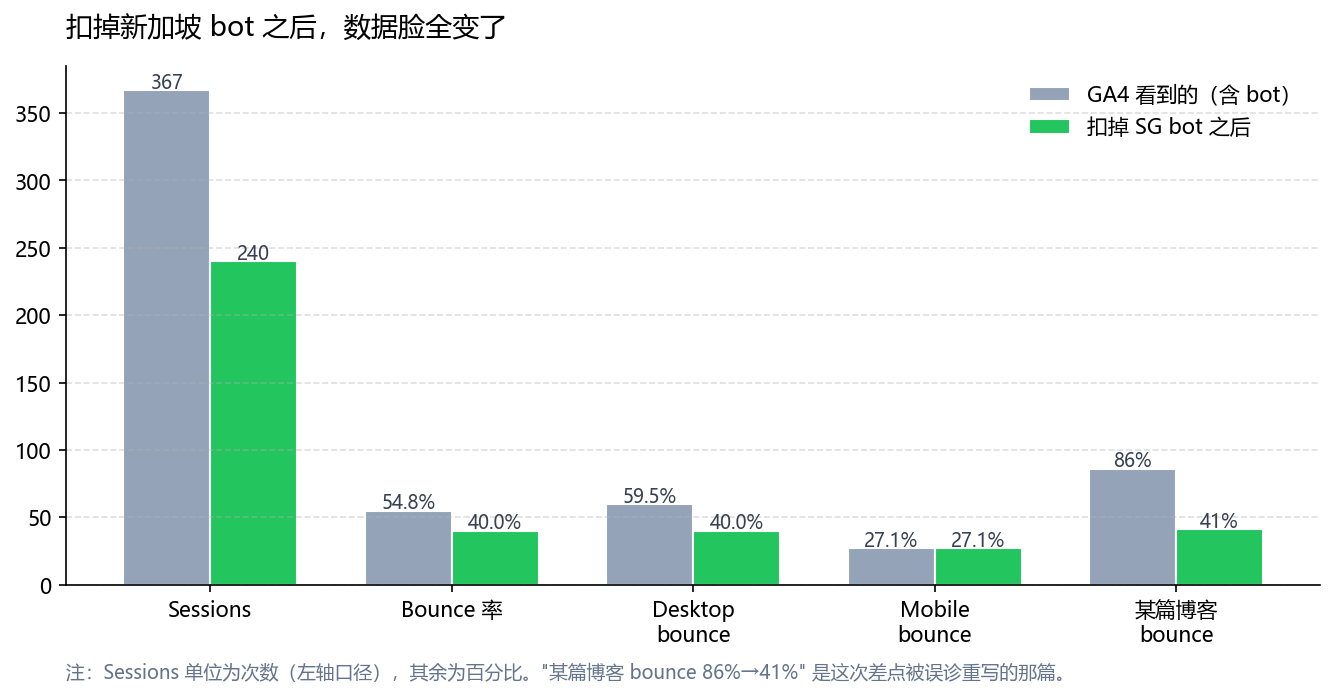
第一个坑:一篇我自己挺喜欢的博客文章,GA4 里 bounce 86%。我以为是搜索意图错配,那时候我已经开始列重写大纲了。要是没多看一眼数据,我会真的把文章重写一遍。
第二个坑:Desktop bounce 59%,Mobile bounce 27%。一般 DTC 站都是反过来的——手机端体验更糟才对。我没想到桌面端是被 bot 拉的,一开始还在排查 cookie 弹窗、字体加载这些根本不存在的问题。
把新加坡那批扣掉之后再看:
- 那篇 86% bounce 的博客,真实 bounce 是 41%——它一直好好的
- Desktop bounce 跟 Mobile 拉平在 40% 上下,桌面端没坏过
我差点为一篇被机器人刷烂的好文章重写内容,为一个根本不存在的 Mobile bug 改代码。
这一刻总算搞清楚了——好文章是真好,桌面端是真没坏,是数据被刷脏了。
这帮”用户”长什么样
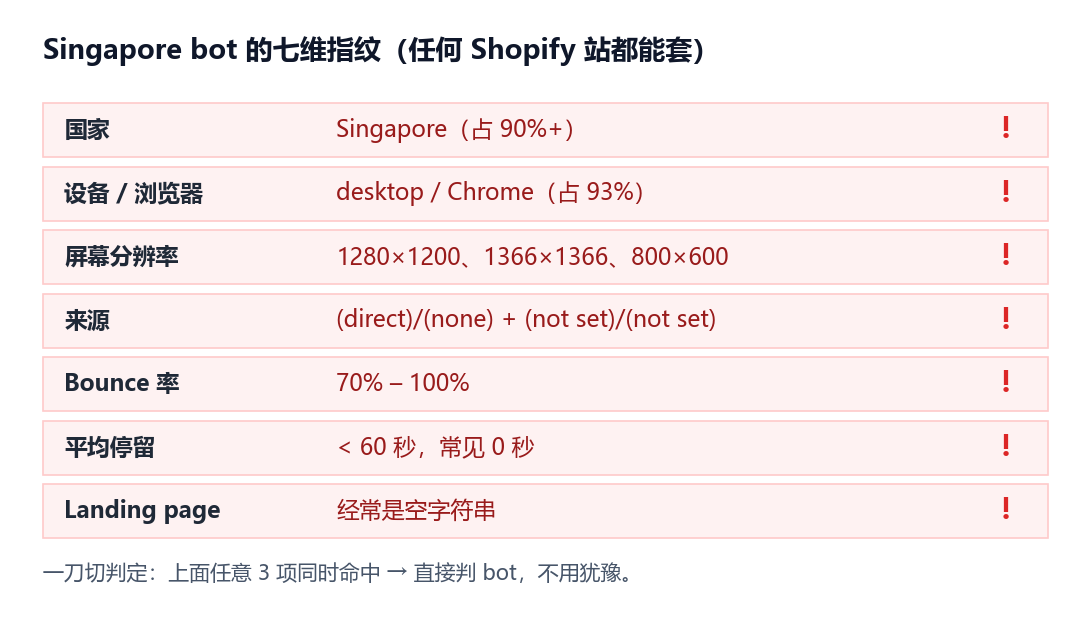
新加坡这坨流量的指纹高度一致,一旦你看清楚一次,下次三秒就能认出来:
| 维度 | 它们的特征 |
|---|---|
| 国家 | Singapore,单一国家压到 90% 以上 |
| 设备 | desktop / Chrome 一个组合占 93% |
| 屏幕分辨率 | 1280x1200、1366x1366、800x600 |
| 来源 | 几乎全是 (direct)/(none) 和 (not set)/(not set) |
| 行为 | bounce 70%–100%,常常 0 秒停留 |
| Landing page | 经常是空字符串 |
注意那几个分辨率。1280×1200、1366×1366 是正方形屏幕,真实人类的显示器没人长这样。800×600 是上世纪 VGA。这三个塞进 GA4 里筛一刀,基本可以一刀切。
那为什么是新加坡?因为新加坡是 Shopify(很多独立站用的电商建站平台)抓站爬虫的机房聚集地,24 小时巡逻抓产品和价格。它们顺手把你 GA4 的 gtag.js(GA4 用来记录访问的脚本)也跑了一遍,于是流量就进来了。
我的站只是其中一个被巡到的而已。任何一家 Shopify 站,只要它公网能访问,都在被抓。
“GA4 自带 bot 过滤不是开着吗”
是开着。但它救不了你。
GA4 设置里那个 “Exclude all hits from known bots and spiders”,挡的是 IAB Tech Lab 公开 bot 名单——Googlebot、Bingbot、Pingdom 这种把”我是机器人”明明白白写在 UA(User-Agent,浏览器自报家门的字符串)里的诚实爬虫。
新加坡这批不一样。它们伪装成 Chrome desktop,UA 字符串、JS(JavaScript,浏览器执行的脚本)执行、Cookie 处理都做得像模像样,主动隐瞒自己是 bot。
打个比方:GA4 自带的过滤就像保安只查穿制服的小偷,制服自己脱掉就放行了。GA4 是白名单逻辑,不做实时检测。指望它兜底兜不住——这事得你自己来。
五步十分钟,分清是问题还是机器人
不限我这家站,下面这套对任何 Shopify 或独立站都通用。下次你看到任何一个不寻常的指标,先按这个顺序拆。
| 步骤 | 拆什么 | 命中信号 |
|---|---|---|
| 1 | 按 country 拆 sessions | SG / HK / VN / RU 任一突然冲到前三 |
| 2 | 按 source 拆 | (direct)/(none) + (not set)/(not set) 占比 > 50%,且集中在第 1 步那些国家 |
| 3 | 按 OS × screenResolution 拆 | 1280×1200、1366×1366、800×600 等正方形/古早分辨率 |
| 4 | 按 landing page + 平均停留拆 | bounce > 80%、停留 < 10 秒、来源 (not set) |
| 5 | 跟 Clarity / Hotjar 对账 | Clarity sessions ÷ GA4 sessions < 50% |
任意 3 项同时命中 → 直接判 bot,不用再细查。
第 4 步那种”bounce > 80% 且来源 (not set)“是机器在做服务器探测,不是有人在看你的内容——遇到这种情况不要去重写文章。第 5 步的对账永远比单看 GA4 准,原因很简单:bot 不会触发 Clarity 的 session 录像。
我把第 1–4 步写成了一个十几行的 Python 脚本,每月跑一次出 4 张表,对着看完心里就有数了。下面这两块直接抄走——会写代码的用脚本,不写代码的用 AI Prompt,殊途同归。
然后才是过滤
诊断清楚之后才谈过滤,反过来不行。先过滤再看数据,你连自己挡掉的是真人还是机器都不知道。
过滤分两层。
第一层:GA4 里能做的,象征意义大于实际
把自己的固定 IP 加成 internal traffic,把明显的 referral spam 加进黑名单——这两件做完只能挡住”我自己刷站”和低级垃圾跳转。伪装成 Chrome 的 SG bot,一个都挡不掉。
第二层:边缘过滤,这层才是真的能挡
我现在的方案是在 Cloudflare 开 Bot Fight Mode + Super Bot Fight Mode,给那几个可疑分辨率和异常 UA 加 challenge(让访问者通过一个验证)。但这块我刚配上没多久,回测数据还没攒够,挡掉了多少、误伤了没有,得跑完一个完整周期才能下结论。那篇我会单独再写。
不要指望”一次配置永久干净”。机器人是流动的,今天 SG 明天可能就 VN,过滤是个长期维护的活。
每月 1 号的固定动作
我现在每月做一次这件事,写下来你可以试着抄过去:
- 跑一次 country / source / OS×screenRes 五维拆解
- 看 SG / VN / RU / HK 在总流量里的占比,超过 15% 就当月数据全部”扣 bot 再判断”
- Clarity sessions ÷ GA4 sessions,比例小于 50% 就说明大半 GA4 流量没被 Clarity 录到(一般是 bot),别再拿 GA 原始数据下决策
- 任何 bounce > 70% 的 landing page,先看来源,再看是否要改内容
- CF 那边新加 challenge 规则后,回头跟 Googlebot/Bingbot 的访问日志对一下,确认没误伤
跑完这五步,第一次会让你怀疑人生(“原来这么多假流量”),但从第二个月开始数据就稳了——那是因为你脑子里有了”bot 过滤层”,肉眼一扫就知道哪条线可信哪条不可信。
那天早上要不是我多点了一下 Clarity,我会真的去重写那篇博客、真的去查那个不存在的 Mobile bug。两件事加起来够我搭进去整整一周。
后来我把这件事抽象成一句话:
任何看上去”突然变好”的指标,先怀疑数据源,再怀疑产品。
GA4 涨了不一定是好事。看到数字之前,先确认那是不是人。
如果你也有自己的独立站,可以拿这套去查一下,看完欢迎留言告诉我你 SG 占比多少——我赌至少 10%。